一、前提条件
假设我们已经有了一个主播表,形式是下面这样:(你可能还会需要其他字段,请自行添加)
| id | 名字 | 票数 |
|---|---|---|
| 1 | 张三 | 100 |
| 2 | 李四 | 210 |
- 票数: 票数越高排名越高,比如一个大炮是10票,这个礼物需要10块钱,一个飞机100票,需要100块钱这样子。
1. 问题讨论
- 问题讨论(1): 表中要不要有主播的排名这个字段?
答案(1): 显然是不需要的,因为票数是频繁变化的,我们通过票数去计算排名即可,如果加上了排名这个字段,那么一个票数更新就会牵扯到一群人甚至整张表内主播的排名更新,这样做的更新代价是非常大的,更新时间也是完全不可接受的。
- 问题讨论(1): 表中要不要有主播的排名这个字段?
二、缓存设计
这里我们先从最简单的设计开始,然后不断的优化
1. 获取排名
上面提到了主播表中没有主播的排名字段,因此每次获取排行版第一页排名靠前的主播就需要排序,但是当有几千、几万的主播时,每次都需要排序,查询时间也会大大增加,无法达到较高的QPS,所以最常见的做法就是通过缓存来实现,即Redis的Sorted Set(ZSet)类型: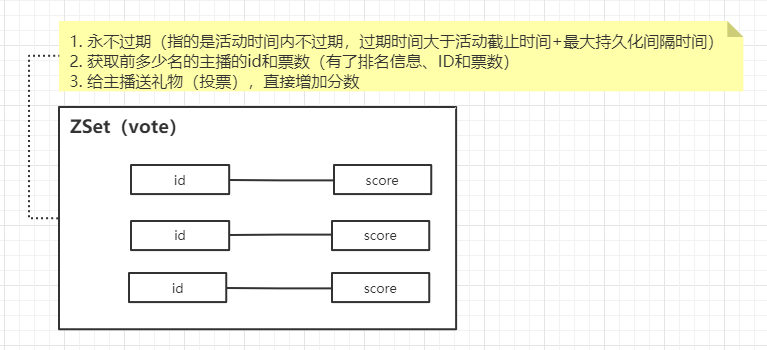
Redis会帮我们根据每个键的分数来维护这个排名,具体的原理可以参考zset的底层数据结构,加上Redis是在内存中的,因此获取排名的速度提升是相当明显的。
- id:即用户的ID
- score:实际存储的就是每个主播的票数
这时我们即可通过ZSet的 zrevrange 函数,获取到排名靠前(票数高)的钱前N名用户。由于是直接操作Redis,因此查询速度可以说是有数量级上的提升。
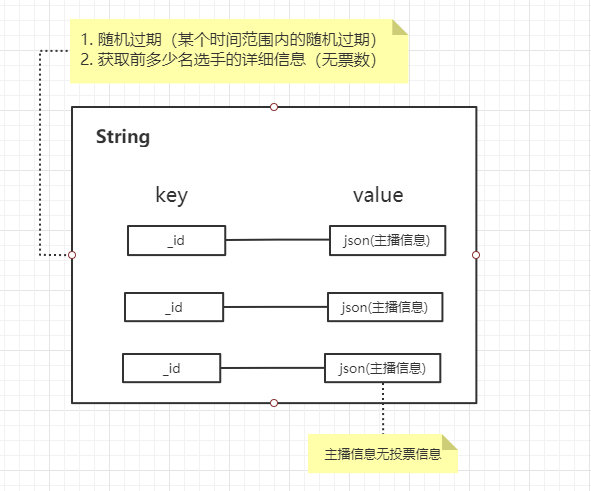
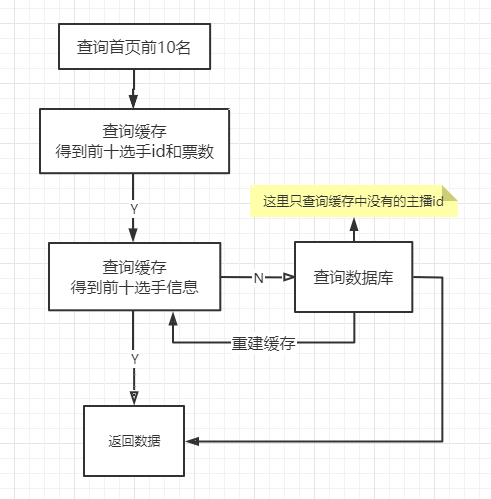
2. 获取排行榜首页主播信息
由于排行榜的首页还需要展示用户的其他信息,因此我们不但需要知道排名靠前的用户的id,还需要查询出用户的详细信息。
相对于直接对票数排序,再获取排名靠前的用户信息来说,我们通过用户ID来查找排行榜用户,速度会快很多(因为无论是MySQL或是MongoDB主键字段是默认加了索引的,因此查询速度还是很快的)
但还是不够快:
即使ID字段有索引,可以加快查询的速度,但是由于排行榜首页的访问量实在是太大了,因此还是要对用户信息加缓存。真实的业务场景下,排行榜首页的人员变动并没有那么大,相当于每次去数据库查询的一组用户的信息变化不大,那么对这些数据加缓存将极大的加快查询速度。
问题讨论(1): 获取用户排名的时候给分数添加索引,这样查询不就快了嘛,何必设计的这么麻烦?
答案(1): 这就犯了一个及其低级的错误,因为给经常变动的数据添加索引反而适得其反,索引本身是B+树等结构,如果是经常变动的数据,索引维护过程反而会消耗大量时间。问题讨论(2): 主播的信息为什么不保存在Hash中,这样就相当于套了一层,管理起来更加方便(一个Hash)
答案(2): Hash是不支持给内部的key-value设置过期时间的,因此这就会形成一个超大的key,没有过期就会导致Hash内部有很多冷数据,浪费内存空间。如果给Hash设置过期时间,就会涉及大key的重建等问题,带来不必要的麻烦问题讨论(3): 主播信息(保存在String类型中)的过期时间如何设置?
答案(3): 可以根据实际情况定10min,20min等(如排名反复变化可将过期时间延长一些),但是切记要在基础过期时间上加一个随机时间,避免同时过期造成的缓存雪崩。
4. 特别提醒
- 在从Redis中获取多个主播详细信息时,请使用pipeline方式,不然则相当于需要N次的网络时间。这是绝对不能忍的。
- 同样的道理,从MySQL 或者MongoDB中查询一组主播ID的时候也需要使用批量查询的方式。
三、总结
本节我们主要根据实际需求来设计了首页数据的缓存结构,主要使用到了Redis的ZSet和String两个类型,并分析了为什么用户信息不能使用Hash来存储。通过这样的方式,我们的首页数据查询接口的QPS基本上就可以上百了。主要的时间消耗在网络传输上。
下一节我们将介绍投票的实现流程和数据持久化部分。
...
...
本文为作者原创文章,未经作者允许不得转载。